Preamble
- This is a followup of previous post about the excellent book from Jason Brownlee: "Generative Adversarial Networks with Python"

Etang Branton face à l'étang Rollet (commune de Lapeyrouse)
PART V: Conditional GANs
Chapter 17: How to develop a Conditional GAN (cGAN)
- Image generation can be conditional on a class label, if available, allowing the targeted g ener ated of images of a given type.
- GANs are effective at image synthesis, that is, generating new examples of images for a target dataset.
- Additional information that is correlated with the input images, such as class labels, can be used to improve the GAN. This improvement may come in the form of more stable training, faster training, and/or generated images that have better quality.
- "By conditioning the model on additional information it is possible to direct the data generation process. Such conditioning could be based on class labels".Conditional Generative Adversarial Nets, 2014.
- In this chapter we are going to play with the fashion MNIST dataset:

Plot of the first 100 items of Clothing from the Fashion-MNIST Dataset
- Up to the code provided by Jason Brownlee, I ran an unconditional GAN for the Fashion-MNIST dataset. The fitting of the GAN took approximately 15 hours on my iMAC.
- Then I was able to generate new images from the MNIST dataset. The generation is nearly instantaneous. Below you get the 100 generated items of clothing with the unconditional GAN.

Example of 100 generated items of clothing using an unconditional GAN
- Then I ran the conditional GAN for the Fashion-MNIST, which is the core of this chapter. Unfortunately, for the first run, the network collapses at epoch #2, batch #432:
 Crash of conditional GAN at Epoch #2, batch #432
Crash of conditional GAN at Epoch #2, batch #432

- If the loss for the discriminator remains at 0.0 or goes to 0.0 for an extended time, this may be a sign of a training failure and you may want to restart the training process.
- So I decided to run another trial, with same hyper parameters. At Epoch #20, the network seems progressing well with no sign of collapse:
 At Epoch # 20, batch # 202 conditional GAN still running
At Epoch # 20, batch # 202 conditional GAN still running

- It took my iMac about 14 hours to train the conditional GAN model. Fortunately, as always, it took only a minute the to generate a new set of fashion clothes with the trained conditional GAN:
 100 generated items of clotting using a conditional GAN
100 generated items of clotting using a conditional GAN - When you compare the two generated set of images, the one with the unconditional GAN and the one with the conditional GAN, you remark the classification done by the conditional GAN.
- So now imagine a designer who starts with a big set of clothes used for years. With an unconditional GAN, he can be inspired by a completely new set of clothes generated automatically and most importantly taking into account the extracted features that made clothes popular and fashioned in the past. If the same designer is provided with a set of clothes generated by a conditional GAN, he will receive a set of classified items of shoes for example, or pants.
- The best way to design models in KERAS to have multiple inputs is by using the Functional API, as opposed to the Sequential API used for the unconditional GAN.

Chapter 18: How to Develop an Information Maximizing GAN (InfoGAN)
- The Information Maximizing GAN, or InfoGAN for short, is an extension to the GAN architecture that introduces control variables that are automatically learned by the architecture and allow control over the generated image, such as style, thickness, and type in the case of generating images of handwritten digits.
- The generation process can be conditioned, such as via a class label, so that images of a specific type can be created on demand. This is the basis for the Conditional Generative Adversarial Network, CGAN or cGAN for short. Another approach is to provide control variables as input to the generator, along with the point in latent space (noise). The generator can be trained to use the control variables to influence specific properties of the generated images. This is the approach taken with the Information Maximizing Generative Adversarial Network, or InfoGAN for short.
- For example, for a dataset of faces, a useful disentangled representation may allocate a separate set of dimensions for each of the following attributes: facial expression, eye color, hairstyle, presence or absence of eyeglasses, and the identity of the corresponding person.
- Control variables are provided along with the noise as input to the generator and the model is trained via a mutual information loss function.
- Training the generator via mutual information is achieved through the use of a new model, referred to as Q or the auxiliary model. The new model shares all of the same weights as the discriminator model for interpreting an input image, but unlike the discriminator model that predicts whether the image is real or fake, the auxiliary model predicts the control codes that were used to generate the image.
- Neither the generator nor the auxiliary models are fit directly; instead, they are fit as part of a composite model.
- The output of the generator model is connected to the input of the discriminator model, and to the input of the auxiliary model.
- I ran the code provided for the Information GAN. The training took about 12 hours. Every 10 epochs, a plot of images is created. Below, I put the plot of the digits generated at Epoch # 10 and the digits generated at Epoch # 50

Plot of 100 random images generated on my iMAC after 10 epochs

Plot of 100 random images generated on my iMAC after 50 epochs
- More epochs does not mean better quality, meaning that the best quality images may not be those from the final model saved at the end of the training. See below the plot after 100 epochs:

- We can now used the trained model to generate new random images:
 Plot of 100 random images generated on my iMAC using the trained model
Plot of 100 random images generated on my iMAC using the trained model

- Lastly, we can generate new random images and use the control code to influence the generated images:
 Plot of 25 images generated on my iMAC with the categorical control code set to 8
Plot of 25 images generated on my iMAC with the categorical control code set to 8

- The InfoGAN is motivated by the desire to disentangle and control the properties in generated images.
- The InfoGAN involves the addition of control variables to generate an auxiliary model that predicts the control variables, trained via mutual information loss function.
Chapter 19: How to Develop an Auxiliary Classifier GAN (AC-GAN)
- The Auxiliary Classifier GAN, or AC-GAN for short, is an extension of the conditional GAN that changes the discriminator to predict the class label of a given image rather than receive it as in input. It has the effect of stabilizing the training process and allowing the generation of large quality images whilst learning a representation in the latent space that is independent of the class label.
- Conditional Image Synthesis with Auxiliary Classifier GANs.
- Generator model:
- input: random point from the latent space, and the class label
- output: generated image
- Discriminator model:
- input: image. These are random points from the latent space, specifically Gaussian distributed random variables.
- output: probability that the provide image is real, probability of the image belonging to each known class
- the model must be trained with two loss functions, binary cross-entropy for the first output layer, and categorical cross-entropy loss for the second output layer.
- Composite model:
- The generator model is not updated directly; instead, it is updated via the discriminator model. This can be achieved by creating a composite model that stacks the generator model on top of the discriminator model.
- The discriminator model is updated in a standalone manner using real and fake examples. Therefore, we do not want to update the discriminator model when updating (training) the composite model; we only want to use this composite model to update the weights of the generator model. This can be achieved by setting the layers of the discriminator as not trainable prior to compiling the composite model.
- The resulting generator learns a latent space representation that is independent of the class label, unlike the conditional GAN. The effect of changing the conditional GAN in this way is both a more stable training process and the ability of the model to generate higher quality images with a larger size than had been previously possible, e.g. 128x128 pixels.
- DCGAN architecture: uses Gaussian weight initialization, BatchNormalization, LeakyRelu, Dropout, and a 2 X 2 stride for downsampling instead of pooling layers.
- The code example, provided by Jason Brownlee, uses the Fashion-MNIST dataset. The AC-GAN training took about 11 hours and 44 minutes on my iMAC. 100 generated images are stored every 10 epochs. Below you get the generated images after 10 epochs. They are of pretty good quality and then you will observe that the images generated at other epochs steps are not better in quality.

AC-GAN Generated Items of Clothing after 10 Epochs on iMAC

AC-GAN Generated Items of Clothing after 80 Epochs on iMAC

AC-GAN Generated Items of Clothing after 100 Epochs on iMAC
- We can then infer a series of new images telling the model that we would like sneakers generated from the trained model:

100 Photos of Sneakers inferred by an AC-GAN on my iMAC
We can then also easily infer a series of coats photos by simply changing the class:






100 Photos of Coats inferred by an AC-GAN on my iMAC
Chapter 20: How to develop a Semi-Supervised GAN (SGAN)
- Semi-supervised learning is the challenging problem of training a classifier in a dataset that contains a small number of labeled examples and a much larger number of unlabeled examples. The Generative Adversarial Network, or GAN, is an architecture that makes effective use of large, unlabeled datasets to train an image generator model via an image discriminator model.
- The semi-supervised GAN, or SGAN, model is an extension of the GAN architecture that involves the simultaneous train of a supervised discriminator, unsupervised discriminator, and a generator model.
- Semi-supervised learning refers to a problem where a predictive model is required and there are few labeled examples and many unlabeled examples.
- The model must learn from the small set of labeled examples and somehow harness the larger dataset of unlabeled examples in order to generalize to classifying new examples in the future.
- The discriminator is trained in two modes: a supervised and unsupervised mode.
- Unsupervised training: in the unsupervised mode, the discriminator is trained in the same way as the traditional GAN, to predict whether the example is either real or fake.
- Supervised training: in the supervised mode, the discriminator is trained to predict the class label of real examples.
- Training in unsupervised mode allows the model to learn useful feature extraction capabilities from a large unlabeled dataset, whereas training in supervised mode allows the model to use the extracted features and apply class labels. The result is a classifier model that can achieve state-of-the-art results on standard problems such as MNIST when trained on very few labeled examples, such as tens, hundreds, or one thousand. Additionally, the train process can also result in better quality images.
- Consider a discriminator model for the standard GAN model. It must take an image as input and predict wether it is real or fake. More specifically, it predicts the likelihood of the input being real. The output layer uses a sigmoid activation function to predict a probability value in [0, 1] and the model its typically optimized using a binary cross-entropy loss function.
- Specifically, we can define one classifier model that predicts whether an input image is real or fake, and a second classifier model that predicts the class for a given model:
- Binary Classifier Model: predicts wether the image is real or fake, sigmoid activation function in the output layer, and optimized using the binary cross-entropy loss function.
- Multiclass Classifier Model: predicts the class of the image, softmax activation function in the output layer, and optimized using the binary cross-entropy function.
- Increasing the epochs to 100 or more results in much higher-quality generated images, but a lower-quality classifier model.
- I ran the SGAN example on my iMac. It took about 3 hours and 18 minutes. It seems to me that the quality of the images delivered with the SGAN are superior to the quality of the images provided by a LSGAN (Least Squares GAN):
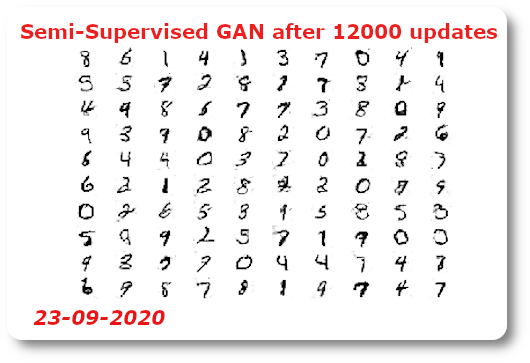
Handwritten digits generated with a Semi-Supervised GAN
- The quality of the generated images is good even the relatively small numbers of trains epochs.
- Then I evaluated the model using the entire training and test dataset with the different trained model obtained during the 10 epochs. The best performance was reached after 6600 batches:
- Train accuracy: 95.317%
- Test accuracy: 95.490%
PART VI: Image Translation
Chapter 21: Introduction to Pix2Pix
- Image-to-image translation is the controlled conversion of a given source image to a target image. An example might be the conversion of black and white photographs to color photographs. Image-to-image translation is a challenging problem and often requires specialized models and loss functions for a given translation task or dataset. The Pix2Pix GAN is a general approach for image-to-image translation. Pix2Pix GAN changes the loss function so that the generated image is both plausible in the content of the target domain, and is a plausible translation of the input image.
- "In analogy to automatic language translation, we define image-to-image translation, we define automatic image-to-image translation as the task of translating one possible representation of a scene into another, given sufficient training data." Image-to-Image Translation with Conditional Adversarial Networks, 2016.
- Pix2Pix is a Generative Adversarial Network, or GAN, model designed for general purpose image-to-image translation.
- Pix2Pix GAN is an implementation of the cGAN where the generation of an image is conditional on a given image.
- Both the generator and discriminator models use standard Convolution-BatchNormalization-Relu (Rectified Linear Activation Unit) blocks of layers as is common for deep convolutional neural networks.
- The generator model takes an image as input, and unlike a standard GAN model, it does not take point from the latent space as input. Instead, the source of randomness comes from the use of dropout layers that are used both during training and when a prediction is made.
- The Pix2Pix model uses a PatchGAN. This is a deep convolutional network designed to classify patches of an input image as real or fake, rather than the entire image.
- The generator model is trained using both the adversarial loss for the discriminator model and the L1 or mean absolute pixel difference between the generated translation of the source image and the expected target image.
Chapter 22: How to Implement Pix2Pix Models
- The Pix2Pix GAN is a generator model for performing image-to-image translation trained on paired examples. For example, the model can be used to translate images of daytime to nighttime, or from sketches of products like shoes to photographs of products. The benefit of the Pix2Pix model is that compared to other GANs for conditional image generation, it is relatively simple and capable of generating large high-quality images across a variety of image translation task.
- The Pix2Pix GAN has been demonstrated on a range of image-to-image translation tasks such as converting maps to satellite photographs, black and white photographs to color, and sketches of products to product photographs.
- « we design a discriminator architecture - which we term a PatchGAN - that only penalizes structure at the scale of patches. This discriminator tries to classify if each N × N patch in an image is real or fake. We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D » Image-to-Image translation with Conditional Adversarial Networks, 2016
- Indeed, since the release of the pix2pix software associated with this paper, a large number of internet users (many of them artists) have posted their own experiments with our system, further demonstrating its wide applicability and ease of adoption without the need for parameter tweaking.
- The PatchGAN configuration is defined using a shorthand notation as: C64-C128-C256C512, where C refers to a block of Convolution-BatchNorm-LeakyReLU layers and the number indicates the number of filters.
- Unlike traditional generator models in the GAN architecture, the U-Net generator does not take a point from the latent space as input. Instead, dropout layers are used as a source of randomness both during training and when the model is used to make a prediction, e.g. generate an image at inference time. Similarly, batch normalization is used in the same way during training and inference, meaning that statistics are calculated for each batch and not fixed at the end of the training process.
- Tanh activation function is used in the output layer, common to GAN generator models.
- The discriminator model can be updated directly, whereas the generator model must be updated via the discriminator model.
Chapter 23: How to Develop a Pix2Pix End-to-End
- The Pix2Pix Generative Adversarial Network, or GAN, is an approach to training a deep convolution always neural network for image-to-image translation tasks.The careful configuration of architecture as a type of image-conditional GAN allows for both the generation of large images compared to prior GAN models (e.g. such as 256 x 256 pixels) and the capability of performing well on a variety of different image-to-image translation tasks.
- The code provided in the book is developing the Pix2Pix model for translating satellite photos to Google maps images. The second part of the chapter is a piece of code that does the reverse: developing a Pix2Pix model to translate Google Maps to plausible image satellite.
- Other examples of Image-to-Image are provided.
Chapter 24: Introduction to the Cycle GAN
- Image-to-image translation involves generating a new synthetic version of a given image with a specific modification, such as translating a summer landscape to winter. Training a model for image-to-image translation typically requires a large dataset of paired examples. These datasets can be difficult and expensive to prepare, and in some cases impossible, such as photographs of paintings by long dead artists. The CycleGAN is a technique that involves the automatic training of image-to-image translation models without paired examples. The models are trained in an unsupervised manner using a collection of images from the source and target domain that do not need to be related in any way.
- The GAN architecture is an approach to training a model for image synthesis that is comprised of two models: a generator model and a discriminator model. The generator takes a point from a latent space as input and generates new plausible images from the domain, and the discriminator takes an image as input and predicts whether it is real (from a dataset) or fake (generated). Both models are trained in a game, such that the generator is updated to better fool the discriminator and the discriminator is updated to better detect generated images. The CycleGAN is an extension of the GAN architecture that involves the simultaneous training of two generator models and two discriminator models.
- The CycleGAN uses an additional extension to the architecture called cycle consistency. This is the idea that an image output by the first generator could be used as input to the second generator and the output of the second generator should match the original image. The reverse is also true: that an output from the second generator can be fed as input to the first generator and the result should match the input to the second generator. Cycle consistency is a concept from machine translation where a phrase translated from English to French should translate from French back to English and be identical to the original phrase. The reverse process should also be true.
- An excellent paper is describing all the possibilities of image translation with paintings of Monnet.
Part VII: Advanced GAN
Chapter 27: Introduction to the BIGGAN
- More recently, work has focused on the effective application of the GAN for generating both high-quality and larger images.
- BigGAN is designed for class-conditional image generation. That is, the generation of images using both a point from latent space and image class information as input.
- The contribution of the BigGAN model is the design decisions for both the models and the training process.




Set of images generated by a BIG GAN
Chapter 28: Introduction to the progressive Growing GAN
- Progressive growing GAN models are capable of generating photorealistic synthetic faces and objects at high resolution that are remarkably realistic.
- A problem with GANs is that they are limited to small dataset sizes, often a few hundred pixels and often less than 100-pixel square images.
- Generating high-resolution images is believed to be challenging for GAN models as the generator must learn how to output both large structure and fine details at the same time.
- Large images, such as 1024-pixel square images, also require significantly more memory, which is in relatively limited supply on modern GPU hardware compared to main memory.
- A solution to the problem of training stable GAN models for larger images is to progressively increase the number of layers during the training process.
- Progressive Growing GAN requires that the capacity of both the generator and discriminator model be expanded by adding layers during the training process.
- Unlike greedy layer-wise pre-training, progressive growing GAN involves adding blocks of layers and phasing in the addition of the blocks of layers rather than adding them directly.
- All existing layers in both networks remain trainable throughout the training process.
 Examples of Photorealistic Generated Faces Using Progressive Growing GAN
Examples of Photorealistic Generated Faces Using Progressive Growing GAN

Chapter 29: Introduction to the StyleGAN
- The StyleGAN is an extension of the progressive growing GAN.
- The StyleGAN generator no longer takes a point from the latent space as input; instead, there are two new sources of randomness used to generate a synthetic image: a standalone mapping network and noise layers.
- The use of different style vectors at different points of the synthesis network gives control over the styles of the resulting image at different levels of detail. For example, blocks of layers in the synthesis network at lower resolutions (e.g. 4 × 4 and 8 × 8) control high-level styles such as pose and hairstyle. Blocks of layers in the middle of the network (e.g. as 16 × 16 and 32 × 32) control hairstyles and facial expression. Finally, blocks of layers closer to the output end of the network (e.g. 64 × 64 to 1024 × 1024) control color schemes and very fine details.
- A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
- A video explaining the capacity explained in the paper above is demonstrating a Style GAN generated images: very impressive.
- The code is free, so that you can apply it to your own set of images.
 These people are not real, they were produced by our generator that allows control over different aspects of the image
These people are not real, they were produced by our generator that allows control over different aspects of the image

Conclusion
- This ends up the series of book from Jason Brownlee.
- This book related to GAN is certainly the most complex but also the most interesting one as GAN are very promising.
- Big thanks to Jason Brownlee who leads me to this journey of deep neural network up to the most sophisticated neural network like the GANs.
- This post is only a summary of the book, the essence is in the book itself.