
The more I learn about Deep Learning, the more I feel that this field is never ending and the knowledge required to master that domain is infinite. I am happy to start this 5th book from Jason Brownlee whose promise in his introduction is that by the end of the book I should be "get good at LSTMs fast". According to Jason Brownlee, "Long Short-term Memory (LSTMs) recurrent neural networks are one of the most interesting types of deep learning at the moment".
Chapter 1: What are LSTMs?
- "Sequence-to-sequence prediction is a subtle but challenging extension of sequence prediction, where, rather than predicting a single next value in the sequence, a new sequence is predicted that may or may not have the same length or be of the same time as the input sequence. This type of problem has recently seen a lot of study in the area of automatic text translation (e.g. translating English to French) and may be referred to by the abbreviation seq2seq."
- "Long Short-Term Memory (LSTM) is able to solve many time series tasks unsolvable by feedforward networks using fixed size time windows."
- "LSTMs have internal state, they are explicitly aware of the temporal structure in the inputs, are able to model multiple parallel input series separately, and can step through varied length input sequences to produce variable length output sequences, one observation at a time."
- "The computational unit of the LSTM network is called the memory cell, memory block, or just cell for short. The term neuron as the computational unit is so ingrained when describing MLPs that it too is often used to refer to the LSTM memory cell. LSTM cells are comprised of weights and gates."
- Applications of LSTMs:
- Automatic Image Caption Generation
- Automatic Translation of text
- Automatic handwriting generation
- Limitations of LSTMs:
- "If your problem looks like a traditional autoregression type problem with the most relevant lag observations within a small window, then perhaps develop a baseline of performance with an MLP and sliding window before considering an LSTM."
Chapter 2: How to train LSTMs
- Backpropagation refers to two things:
- The mathematical method used to calculate derivatives and an application of the derivative chain rule.
- The training algorithm for updating network weights to minimize error.
- Backpropagation is a supervised learning algorithm that allows the network to be corrected with regard to the specific errors made.
- Backpropagation algorithm:
- Present a training input pattern and propagate it through the network to get an output.
- Compare the predicted outputs to the expected outputs and calculate the error.
- Calculate the derivatives of the error with respect to the network weights.
- Adjust the weights to minimize the error.
- Repeat
- Recurrent Neural Network: the deeper layers take as input the output of the prior layer as well as a new input time step.
- Each time step requires a new copy of the network which in turn takes more memory, especially for large networks with thousands or millions of weights.
- Backpropagation Through Time, or BPTT, is the application of the Backpropagation training algorithm to Recurrent neural Networks.
- Truncated Backpropagation Through Time, or TBPTT, is a modified version of the BPTT training algorithm for recurrent neural networks where the sequence is processed one step at a time and periodically an update is performed back for a fixed number of time steps.
- The KERAS deep learning library provides an implementation of TBPTT for training recurrent neural networks.
- You must split long sequences into subsequences that are both long enough to capture relevant context for making predictions, but short enough to efficiently train the network.
Chapter 3: How to prepare data for LSTMs
- Normalization is a rescaling of the data from the original range so that all values are within the range of 0 and 1.
- Standardizing a dataset involves rescaling the distribution of values so that the mean of observed values is 0 and standard deviation is 1. This can be thought of as subtracting the mean value or centering the data.
- One Hot Encoding
- Sequence padding
- Sequence truncating
- "For example, it may make sense to truncate very long text in a sentiment analysis for efficiency, or it may make sense to pad short text and let the model learn to ignore or explicitly mask zero input values to ensure no data is lost."
- Pandas shift() function
Chapter 4: How to develop LSTMs in KERAS
- Input must be three-dimensional, comprised of samples, time steps, and features.
- You can convert a 1D or 2D dataset to a 3D dataset using the reshape() function in NumPy.
- You can specify the input_shape argument that expects a tuple containing the number of time steps and the number of features.
 Predictive modeling, standard activation function and loss function relation
Predictive modeling, standard activation function and loss function relation- Compilation transforms the simple sequence of layers that we defined into a highly efficient series of matrix transforms in a format intended to be executed on your GPU or CPU.
- Once the network is compiled, it can be fit, which means adapting the weights on a training dataset.
- Each epoch can be partitioned into groups of input-output patter pairs called batches. This defines the number of patterns that the network is exposed to before the weights are updated within an epoch.
- Batch: a pass through a subset of samples in the training dataset after which the network weights are updated. One epoch is comprised of one or more batches.
- Each LSTM memory unit maintains internal state that is accumulated. By default, the internal state of all LSTM memory units in the network is reset after each batch, e.g. when the network weights are updated.
Chapter 5: models for sequence prediction
- LSTMs work by learning a function (f(...)) that mass input sequence values (X) onto output sequence values (y)
- Models and applications:



Chapter 6: How to develop vanilla LSTMs
- A simple LSTM configuration is the vanilla LSTM. It is named Vanilla in this book to differentiate it from deeper LSTMs and the suite of more elaborate configurations
Chapter 7: how to develop stacked LSTMs
- The stacked LSTM is a model that has multiple hidden LSTM layers where each layer contains multiple memory cells.
- It is the depth of neural networks that is generally attributed to the success of the approach on a wide range of challenging prediction problems.
- A stacked LSTM architecture can be defined as an LSTM model comprised of multiple LSTMs layers.
- Each LSTMs memory cell requires a 3D input.
- In time series forecasting, it is good practice to make the series stationary, that is remove any systematic trends and seasonality from the series before modeling the problem.
Chapter 8: How to develop CNN LSTMs
- The CNN LSTM architecture involves using Convolutional Neural Network (CNN) layers for feature extraction on input data combined with LSTMs to support sequence prediction.
- CNN LSTMS were developed for:
- Activity recognition
- Image description
- Video description
- Speech recognition
- Natural Language Processing
- The architecture is appropriate for problems that:
- have spatial structure in their input such as the 2D structure or pixels in an image or the 1D structure of words in a sentence, paragraph or document.
- have a temporal structure in their input such as the order of images in a video, or words in text.
- The CNN model is transforming a single image from input pixels into an internal matrix or vector representation.

- We can define a CNN LSTM model in KERAS by first defining the CNN layer or layers, wrapping them in a TimeDistributed layer and then defining the LSTM and output layers.


Chapter 9: How to develop Encoder-Decoder LSTMs
- Sequence-to-sequence prediction problems, or seq2seq for short
- One approach to seq2seq prediction problems that has proven very effective is called the Encoder-Decoder LSTM. This architecture is comprised of two models: one for reading the input sequence and encoding it into a fixed-length vector, and a second for decoding the fixed-length vector and outputting the predicted sequence.
- It is clear that the RNN Encoder-Decoder captures both semantic and syntactic structures of the phrase.
- It is natural to use a CNN as an image "encoder", by first pre-training it for an image classification task and using the last hidden layer as an input that the RNN decoder that generates sentences.
- Applications:
- Machine translation
- Learning to execute
- Image captioning
- Conversational modeling
- Movement classification
- The encoder-decoder can be implemented directly in KERAS.

Abreuvoir - 1951
Chapter 10: How to develop bidirectional LSTMs
- We were surprised by the extent of the improvement obtained by reversing the words in the source sentences.
- Bidirectional LSTMs focus on the problem of getting the most out of the input sequence by stepping through input time steps in both the forward and backward directions.
- "...relying on knowledge of the future seems at first sight to violate causality. How can we base our understanding of what we've heard on something that hasn't been said yet? However, human listeners do exactly that. Sounds, words, and even whole sentences that at first mean nothing are found to make sense in the light of future context." - Framewise Phoneme Classification with bidirectional LSTM and other Neural Network Architectures, 2005 -
- Bi-directional LSTMs were developed for speech recognition.
- The cumulative sum of the input sequence can be calculated using the cumsum() NumPy function.
Chapter 11: How to develop generative LSTMs
- LSTMs can be used as a generative model. Given a large corpus of sequence data, such as text documents, LSTM models can be designed to learn the general structural properties of the corpus, and when given a seed input, can generate new sequences that are representative of the original corpus.
- The problem of developing a model to generalize a corpus of text is called language modeling in the field of Natural Language Processing.
- The approach has also been applied to different domains where a large corpus of existing sequence information is available and new sequences can be generated one step at a time, such as:
- handwriting generation
- music generation
- speech recognition
Chapter 12: How to diagnose and tune LSTMs
- Certainly one of the most interesting chapter as the author suggest many code examples on how to tune and address common LSTMs problems: underfitting, overfitting, goodfitting. Also a grid search example on how to find the best number of memory cells.

LSTMs are stochastic, meaning that you will get a different diagnostic plot each run

Underfitting
An under fit model is one that is demonstrated to perform well on the training dataset and poor on the test dataset. This can be diagnosed from a plot where the training loss is lower than the validation loss, and the validation loss has a trend that suggests further improvements are possible.

Underfitting with more epochs

Overfitting
An overfitting model is one where performance on the train set is good and continues to improve, whereas performance on the validation set improves to a point and then begins to degrade. This can be diagnosed from a plot where the train loss slopes down and the validation slopes down, hits an inflection point, and starts to slope up again.

Goodfit
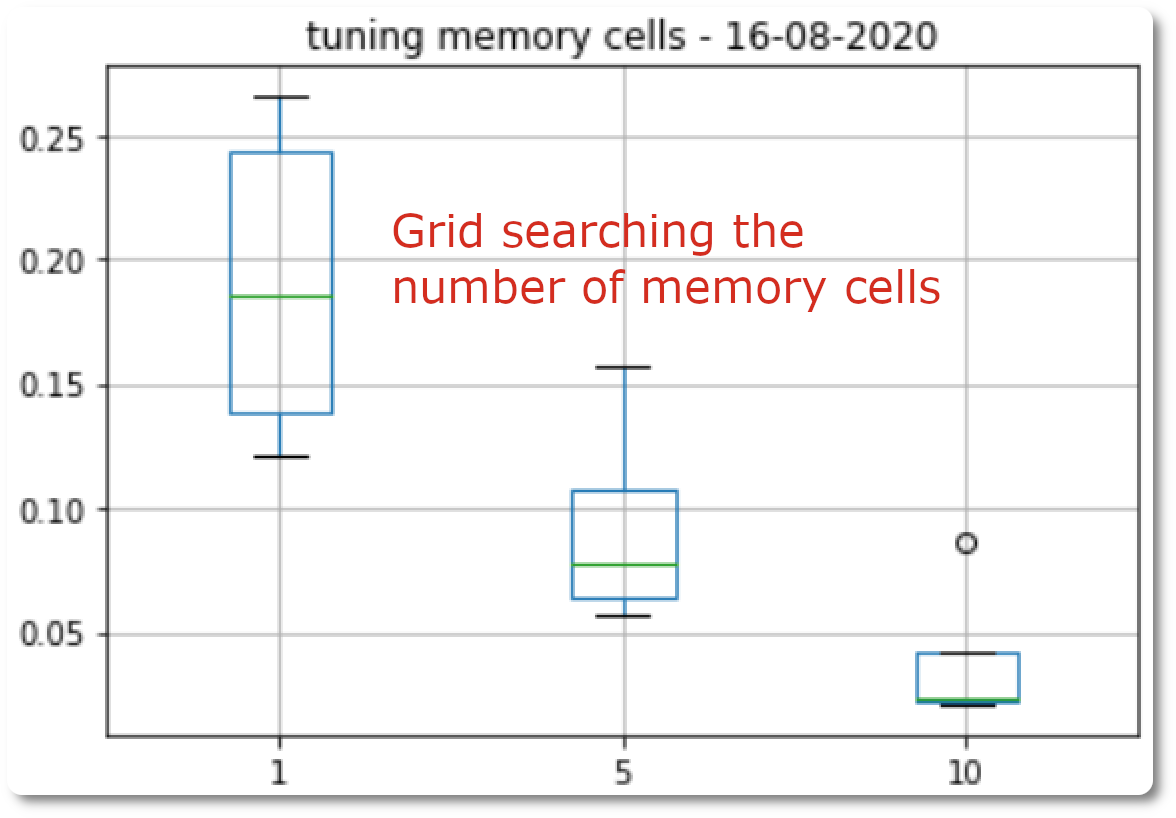
Box and whisker plots of memory cells
Chapter 13: How to make predictions with LSTMs
- « A final LSTM model is one that you use to make predictions on new data. That is, given new examples of input data, you want to use the model to predict the expected output. This may be a classification (assign a label) or a regression (a real value). »
- « Creating a train and test split of your dataset is one method to quickly evaluate the performance of an algorithm on your problem. The training dataset is used to prepare a model, to train it. We pretend the test dataset is new data where the output values are withheld from the algorithm. We gather predictions from the trained model on the inputs from the test dataset and compare them to the withheld output values of the test set. »
- « Using k-fold cross-validation is a more robust and more computationally expensive way of calculating this same estimate. We use the estimate of the skill of our LSTM model on a training dataset as a proxy for estimating what the skill of the model will be in practice when making predictions on new data. »
- « You finalize a model by applying the chosen LSTM architecture and configuration on all of your data. There is no train and test split and no cross-validation folds »
- « You can save the model architecture (e.g. layers and how they connect) and weights (arrays of numbers) to separate files. I recommend this approach as it allows you to develop updated model weights and replace one file while ensuring the model architecture is left unchanged. »
- « Keras provides two formats for preserving the model architecture: JSON and YAML formats. The benefit of these formats is that they are human readable. »
Chapter 14: How to update LSTM models
- « I recommend storing model weights and model structure in separate configuration files.»
Conclusion
- This relatively short book of only 14 chapters as compared to the others book which usually range in the 28 chapters length, is a deep dive (at least for me) in LSTM network.
- The good side for me is that the LSTM examples I went through in the previous books are here more explained in details and I think my previous readings were helpful.
- The fact that you review notions in a different context help me to memorise the LSTM characteristics and how to manipulate LSTMs.
- What I liked less was the contrived examples (sum, mul, shapes...), although I understand that this was necessary for didactic purposes. I would have preferred concrete examples from real life.
- What I liked the most from this book was the tuning of hyper parameters of the LSTM (Chapter 12)
- I am amazed at this huge quantity of knowledge shared by Jason Brownlee, and also his didactic way of explaining.
1 commentaire:
Very impressive Dominique!
Enregistrer un commentaire