Preamble
- I am currently reading and practicing the sixth book from Jason Brownlee. Actually I don't remember having read more than six books of the same author in the past. This is an indication that I still get a lot of value out of these books.
- It's true that you get knowledge at many corners in the book: at the turn of every single sentence in the book, you're at risk at learning something or viewing a topic from a different angle.
- The fact that you're learning by doing is also a key principle.
Introduction
- This post is a recap of all my notes and investigation about the book from Jason Brownlee: "Deep Learning for Natural Language Processing".
Part II - Foundations
Chapter 1: Natural Language Processing
- Natural Language Processing, or NLP for short, is broadly defined as the automatic manipulation of natural language, like speech and text, by software.
- Linguistics is the scientific study of language, including its grammar, semantics and phonetics.
- The interesting problems in natural language understanding resist clean mathematical function.
- Computational linguistic is the modern study of linguistics using the tools of computer science.
- The statistical approach to studying natural language now dominates the field.
- Linguistic science, permitting discussion of both classical linguistics and modern statistics method.
- Statistical NLP aims to do statistical inference for the field of natural language.
Chapter 2: Deep learning
- Andrew Ng: The core of deep learning is that we now have fast enough computers and enough data to actually train large neural networks.
- ... almost all the value today of deep learning is through supervised learning or learning from labeled data.Automatic feature extraction from raw data, also called feature learning.
- Deep learning allows computational models that are composed of multiple processing layers to learn representations of stat with multiple levels of abstraction.
- "Deep" in deep learning is hype. Andrew prefers "reinforcement learning".
- Modern state of the art deep learning is focused on training deep (many layered) neural network models using the back propagation algorithm.
Chapter 3: Promise of deep learning for natural language
- Deep learning methods have the ability to learn feature representations rather than requiring experts to manually specify and extract features from natural language.
- The promise of deep learning methods is the automatic feature learning.
- The large blocks of an automatic speech recognition pipeline are speech processing, caustic models, pronunciation models, and language models. The problem is, the properties and importantly the errors of each subsystem are different. This motivates the need to develop one neural network to learn the whole problem end-to-end.
Chapter 4: How to develop deep learning models with Keras
- Connecting layers: the layers in the model are connected pairwise. A bracket or functional notation is used, such that after the layer is created, the layer from which the input to the current layer comes from is specified:
- visible : Input(shape=(2,))
- hidden = Dense(2)(visible)
- Keras provides a Model class:
- model = Model(inputs=visible, outputs=hidden)
Part III - Data preparation
Chapter 5: How to clean text manually and with NLTK
- Have a strong idea about what you're trying to achieve.
- The Natural Language Toolkit, or NLTK for short, is a Python library written for working and modeling text.
- NLTK provides the sent_tokenize() function to split text into sentences.
- Stop words are those words that do not contribute to the deeper meaning of the phrase. They are the most common words such as: the, a and is.
- Stem words: Stemming refers to the process of reducing each word to its root or base. For example fishing, fished, fisher all reduce to the stem fish.
- Things always jump out at you when to take time to review your data.
Chapter 6: How to prepare text data with scikit-learn
- The text must be parsed to remove words, called tokenization. Then the words need to be encoded as integers or floating point values for use as input to a machine learning algorithm, called feature extraction (or vectorization). The scikit-learn library offers easy-to-use tools to perform both tokenization and feature extraction of your text data.
- Algorithms take vectors of numbers as input, therefore we need to convert documents to fixed-length vectors of numbers.
- A simple and effective model for thinking about text documents in machine learning is called the Bag-of-Words, or BoW.
- The model is simple in that it throws away all the order information in the words and focuses on the occurence of words in a document. This can be done by assigning each word a unique number.
- This is the bag-of-words model, where we are only concerned with encoding schemes that represent what words are present or the degree to which they are present in encoded documents without any information of order.
- TF-IDF: Term Frequency - Inverse Document Frequency. The IDF of a rare term is high, whereas the IDF of a frequent term is likely to be low.
Chapter 7: How to prepare text data with Keras
- You cannot feed raw text directly into deep learning models. Text data must be encoded as numbers to be used as input or output for machine learning and deep learning models, such as word embeddings.
- Words are called tokens and the process of splitting text into tokens is called tokenization.
- It is popular to represent a document as a sequence of integer values, where each word in the document is represented as a unique integer. Keras provides the one_hot() function that you can use to tokenize and integer encode a text document in one step.
- Keras provides the hashing_trick() function that tokenizes and the integer encodes the document, just as the one_hot() function.
- Keras provides the Tokenizer class for preparing text documents for deep learning.
Part IV - Bag-of-Words
Chapter 8: The Bag-of-Words model
- The bag-of-words is a way of representing text data when modeling text with machine learning algorithms. The bag-of-words model has seen great success in problems such as language modeling and document classification.
- A popular and simple method of feature extraction with text data is called the bag-of-words model of text.
- It is called bag-of-words, because any information about the order or structure of words in the document is discarded.
- As the vocabulary size increases, so does the vector representation of documents.
- A vector with lot of zero scores, called a sparse vector or sparse representation. Sparse vector require more memory and computational resources when modeling and the vast number of positions or dimensions can make the modeling process very challenging for traditional algorithms.
- A bag-of-bigrams representation is much more powerful than bag-of-words.
- example of bigram: "please turn"
Chapter 9: How to prepare movie review data for sentiment analysis
- When working with predictive models of text, like a bag-of-words model, there is a pressure to reduce the size of the vocabulary. The larger the vocabulary, the more sparse the representation of each word or document.
Chapter 10: develop a neural Bag-of-words model for sentiment analysis
- We can develop a vocabulary as a Counter, which is a dictionary mapping of words and their count that allows us to easily update and query.
- A bag-of-words model is a way of extracting features from text so that the text input can be used with machine learning algorithms like neural networks. Each document is converted into a vector representation.
- We will use the Keras API to convert reviews to encoded document vectors. Keras provides the Tokenizer class that can do some of the cleaning and vocab definition tasks. The tokenizer class is convenient and will easily transform documents into encoded vectors.
- Because neural networks are stochastic, they can produce different results when the same model is fit on the same data. This is mainly because of the random initial weights and the shuffling of patterns during mini batch gradient descent.
- The texts_to_matrix() function for the Tokenizer in the Keras API provides 4 different methods for scoring words:

Encoding schemes for texts_to_matrix()
Part V: Word Embeddings
Chapter 11: The Word Embedding Model
- Word embeddings are considered to be among a small number of successful applications of unsupervised learning at present.
- The word2vec tool takes a text corpus as input and produces the word vectors as output. It first constructs a vocabulary from the training text data and then learns vector representation of words.
- Glove is an unsupervised learning algorithm for obtaining vector representation of words.
Chapter 12: How to Develop Word Embeddings with Gensim
- Embedding algorithms like Word2vec and Glove are key to the state-of-the-art results achieved by neural network models on natural language processing problems like machine translation.
- A word embedding is an approach to provide a dense vector representation of words that capture something about their meaning. Word embeddings are an improvement over simpler bag-of-word model word encoding schemes like word counts and frequencies that result in large and sparse vectors (mostly 0 values) that describe documents but not the meaning of the words.
- The vector space representation of the words provides a projection where words with similar meanings are locally clustered within the space.
- The use of word embeddings over text representations is one of the key methods that has led breakthrough performance with deep neural networks on problems like machine translation.
- Gensim is an open source Python library for natural language processing, with a focus on topic modeling. It is billed as "topic for humans". It supports an implementation of the Word2Vec word embedding for learning new word vectors from text.
- Below is a small example of Word2Vec usage and visualization with PCA (Principal Component Analysis) on a single sentence:
 Plotting word vectors
Plotting word vectors - Training your own word vectors may be the best approach for a given NLP problem. But it can take a long time, a fast computer with a lot of RAM and isk space, and perhaps some expertise in finessing the input data and training algorithm. An alternative is to simply use an existing pre-trained word embedding.
- A pre-trained model is nothing more than a file containing tokens and their associated word vectors. The pre-trained Google Word2Vec model was trained on Google news data (about 100 billion words); it contains 3 million words and phrases and was fit using 300-dimensional word vectors. It is a 1.53 Gigabyte file.
- You can play arithmetic with vectors. Example (king - man) + woman => the Word2Vec will give you ... queen.

Chapter 13: How to Learn and Load Word Embeddings in Keras
- The position of a word within the vector space is learned from text and is based on the words that surround the word when it is used. The position of a word in the learned vector space is referred to as its embedding.
- If you wish to connect a Dense layer directly to an Embedding layer, you must first flatten the 2D output matrix to a 1D vector using the Flatten layer.
- "The smaller the vocabulary is, the lower is the memory complexity, and the more robustly are the parameters of the words estimated". Tomas Mikolov word2vec-toolkit
- Keras offers an Embedding layer that can be used for neural networks on text data. The Keras Embedding layer can also used a word embedding learned elsewhere. It is common in the field of Natural Language Processing to learn, save and make freely available word embeddings.
Part VI: Text Classification
Chapter 14: Neural Models for Document Classification
- The modus operandi for text classification involves the use of word embedding for representing words and a Convolutional Neural Network (CNN) for learning how to discriminate documents on classification problems.
- "Convolutional neural networks are effective at document classification, namely because they are able to pick up salient features (e.g. tokens or sequences of tokens) in a way that is invariant to their position within the input sequences". Yoav Goldberg.

CNN Filter and Pooling architecture for Natural Language Processing

Chapter 15: Develop an Embedding + CNN Model for Sentiment Analysis
- We use binary cross-entropy loss function because the problem we are learning is a binary classification problem. (see chapter 4 of Long Short Term Memory Networks with Python)
- The model is trained for 10 epochs, or 10 passes through the training data.
- Increasing the number of epochs even to 40 did not increase the reliability of the predictions of the two examples:

- However increasing the level of detail in the review examples which are submitted for prediction gave a good result:



Chapter 16: Project: Develop an n-gram CNN Model for Sentiment Analysis
- A standard deep learning model for text classification and sentiment analysis uses a word embedding layer and one-dimensional convolutional neural network. The model can be expanded by using multiple parallel convolutional neural networks that read the source document using different kernel sizes. This, in effect, creates a multi-channel convolutional neural network for text that reads texts with different n-gram sizes (groups of words)
- Keras functional API vs Keras sequential API

Birieux
Part VII: Language Modeling
Chapter 17: Neural Language Modeling
- The use of neural networks in language modeling is often called Neural Language Modeling, or NLM for short. Neural network approaches are achieving better results than classical methods both on standalone language models and when models are incorporated into larger models on challenging tasks like speech recognition and machine translation.
- LSTM allow the models to learn the relevant context over much longer input sequences than the simpler feedforward networks.
Chapter 18: How to Develop a Character-Based Neural Language Model
- A language model predicts the next word in the sequence based on the specific words that have come before it in the sequence. It is also possible to develop language models at the character level using neural networks. The benefits of character-based language models is their small vocabulary and flexibility in handing any words, punctuation, and other document structure. This comes at the cost of requiring larger models that are slow to train.
- One hot encode:
- We need to one hot encode each character. That is, each character becomes a vector as long as the vocabulary (38 items) with a 1 marked for the specific character. This provides a more precise input representation for the network. It also provides a clear objective for the network to predict, where a probability distribution over characters can be output by the model and compared to the ideal case of all 0 values with a 1 for the actual next character.
- We can use the to_categorical() function in the Keras API to one hot encode the input and output sequences.
- The model is learning a multi class classification problem, therefore we use the categorical log loss intended for this type of problem. (see chapter 4 of Long Short Term Memory Networks with Python)
- A small example of text generation with "Le dormeur du val", a poem from Arthur Rimbaud, gave me the following results. The highlighted part of the sentences are the one automatically generated by the LSTM network:

Le Dormeur du val
Chapter 19: How to Develop a Word-Based Neural Language Model
- Language modeling involves predicting the next word in a sequence given the sequence of words already present. A language model is a key element in many natural language processing models such as machine translation and speech recognition. The choice of how the language model is framed must match how the language model is intended to be used.
- When making predictions, the process can be seeded with one or few words, then predicted words can be gathered and presented as input on subsequent predictions in order to build a generated output sequence.
- First the Tokenizer is fit on the source text to develop the mapping from words to unique integers. Then sequences of text can be converted to sequences of integers by calling the text_to_sequences() function.
- The following example is a very simple model: with one word as input, the model will learn the next word in the sequence:
 Source text
Source text
Generated text (highlighted) with "Colas" as input seed
Chapter 20: Develop a Neural Language Model for Text Generation
- A language model can predict the probability of the next word in the sequence, based on the words already observed in the sequence. Neural network models are a preferred method for developing statistical language models because they can use a distributed representation where different words with similar meanings have similar representation and because they can use a large context of recently observed words when making predictions.
- A key design decision is how long the input sequences should be. They need to be long enough to allow the model to learn the context for the words to predict.
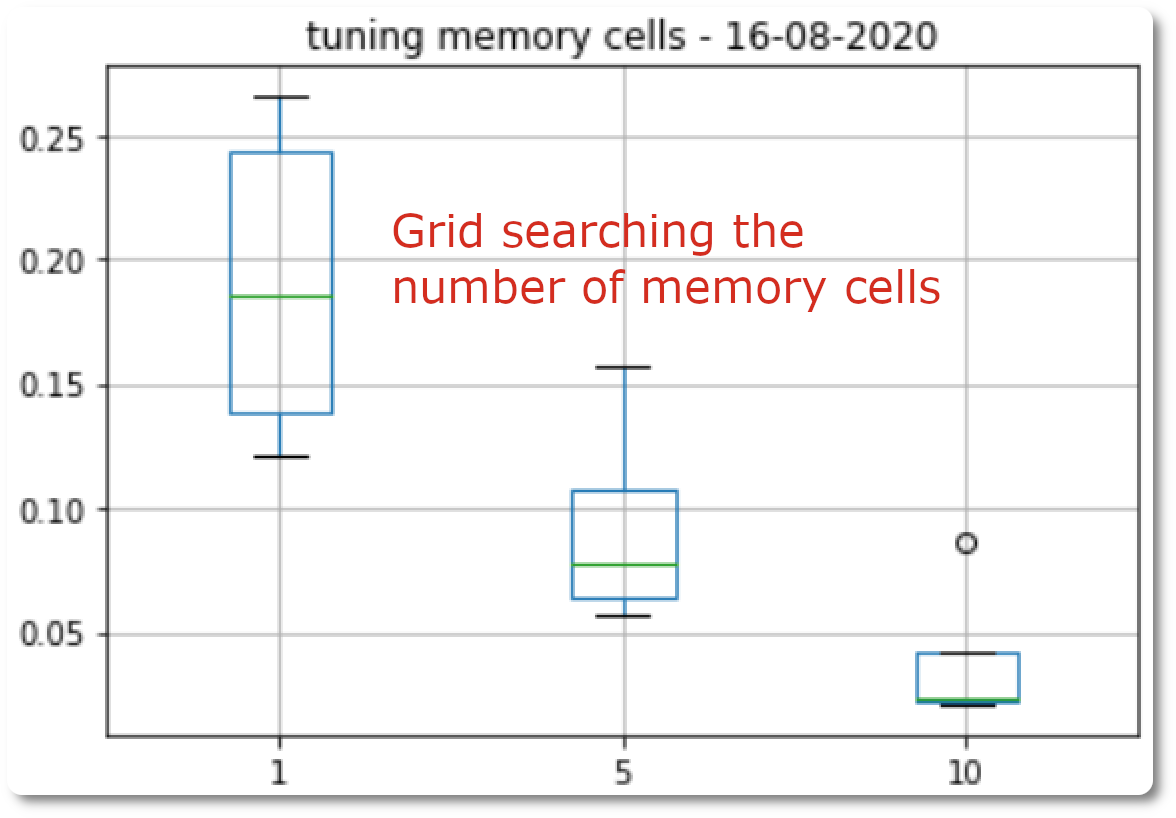
- Vocabulary size is a big deal with language modeling. A smaller vocabulary results in a smaller model that trains faster.
- The model uses a distributed representation for words so that different words with similar meanings will have a similar representation.
- The Tokenizer must be trained on the entire train dataset, which means it finds all of the unique words in the data and assigns a unique integer.
- We can access the mapping of words to integers as a dictionary attribute called word_index on the Tokenizer object.
- Words are assigned values from 1 to the total number of words.
- The learned embedding needs to know the size of the vocabulary and the length of the input sequences.
- The project of this Chapter 20 consists of generating a sequence of 50 words out of a Platon text (quite big: 15802 lines of text) which is trained before with a LSTM network.
- The project is developed in three steps: first is the preparation of the text, then second comes the the training of the network and then comes the generation of the 50 words sequence from a seed of 50 words. The training part for the Platon text took 3 hours and 50 minutes on my iMac. (100 epochs and batch size of 128)
- The 50 words seed sequence generated by the neural network were: "which were attributed by us before to the just seeing that you do not hesitate to rank injustice with wisdom and virtue you have guessed most infallibly he replied then i certainly ought not to shrink from going through with the argument so long as i have reason to think that"
- The 50 generated words by the neural network were: "the same are celebrating in song and intellect with the world of the state and the like in order that he was alive in the days of the soul and the like in order to be sure he said and i will endeavour to explain that they are not a"
- There was an high load on the cpu but no GPU usage:
 cpu usage during the training phase of Platon text
cpu usage during the training phase of Platon text - This project plays in the same courtyard as the text from Victor Hugo I developed previously.

Part VIII: Image Captioning
Chapter 21: Neural Image Caption Generation
- The need to combine breakthroughs from computer vision and natural language processing.
- Image caption generation also named image annotation or image tagging.
- Image tagging combines both computer vision and natural language processing and marks a true challenging problem in broader artificial intelligence.
- Neural network models for captioning involve two main elements:
- feature extraction
- language model
- The feature extraction model is a neural network that given an image is able to extract the salient features, often in the form of a fixed-length vector.
- A language model predicts the probability of the next word in the sequence given the words already present in the sequence.
- It is popular to use a recurrent neural network, such as the Long Short Term Memory network, or LSTM, as the language model.
- This is an architecture developed for machine translation where an input sequence, say it in French, is encoded as a fixed-length vector by an encoder network. A separate decoder network then reads the encoding and generates an output sequence in the new language, say English. A benefit of this approach in addition to the impressive skill of the approach is that a single end-to-end model can be trained on the problem. When adapted for image captioning, the encoder network is a deep convolutional neural network, and the decoder network is a stack of LSTM layers.
- We investigate models that can attend to salient part of an image while generating its caption.


Chapter 22: Neural Network Models for Caption Generation
- Caption generation is a challenging artificial intelligence problem that draws on both computer vision and natural language processing. The encoder-decoder recurrent neural network architecture has been shown to be effective at this problem. The implementation of this architecture can be distilled into inject and merge based models, and both make different assumptions about the role of the recurrent neural network in addressing the problem.
- Inject model: in an inject model, the RNN is trained to predict sequences based on histories consisting both linguistic and perceptual features. From What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator? 2017
- Merge model: in the case of "merge" architectures, the image is left out of the RNN subnetwork, such that the RNN handles only the caption fix, that is, handles only purely linguistic information. From Where to put the Image in an Image Caption generator, 2017.
- "Dense" means fully connected layers with bias: bias allows you to shift the activation function to the left or to the right.
Chapter 23: How to Load and Use a Pre-Trained Object Recognition model
- ImageNet is a research project to develop a large database of images with annotations, e.g. images and their descriptions.
- VGG released two different CNN models, specifically a 16-layer model and a 19-layer model.
- More information related to this topic in the excellent book from Jason Brownlee "Deep Learning for Computer Vision"
Chapter 24: How to Evaluate Generated Text With the BLEU score
- BLEU, or Bilingual Evaluation Understudy, is a score for comparing a candidate translation of text to one or more reference translations. Although developed for translation, it can be used to evaluate text generated for a suite of natural language tasks.
- The Python Natural Language Toolkit library, or NLTK, provides a function called corpus_bleu() for calculating the BLEU score for multiples sentences such as a paragraph or a document.
- The sentence_bleu() and corpus_bleu() scores calculate the cumulative 4-gram BLEU score, also called BLEU-4.
Chapter 25: How to Prepare a Photo Caption Dataset for Modeling
- Flickr8K is a dataset comprised of more than 8000 photos and up to 5 captions for each photo.
- We may want to use a pre-defined feature extraction model, such as the state-of-the-art deep image classification network trained on Image net. The Oxford Visual Geometry Group (VGG) model is popular for this purpose and is available in Keras.
- A generator is the term used to describe a function used to return batches of samples for the model to train on. As a reminder, a model is fit for multiple epochs, where one epoch is one pass through the entire training dataset, such as all photos. One epoch is comprised of multiple batches of examples where the model weights are updated at the end of each batch.
Chapter 26: Develop a Neural Image Caption Model
- The first step in encoding the data is to create a consistent mapping from words to unique integer values. Keras provides the Tokenizer class that can learn this mapping from the loaded description data. The to_lines() convert the dictionary of descriptions into a list of strings and the create_tokenizer() function will fit a Tokenizer given the loaded photo description text.
- There are two input arrays to the model based on the merge-model described by Marc Tanti: one for photo features and one for the encoded text. There is one output for the model which is the encoded next word in the text sequence.
 The Marc Tanti Merge model
The Marc Tanti Merge model The caption generation model
The caption generation model - To reduce overfitting the training dataset, we use a regularization in the form of 50% dropout.
- Training the model took about 5 hours and 24 minutes, on my iMac computer. Each epoch running about in 15 minutes. The best epoch being epoch # 5 with a loss of 3.83631.



BLEU scores evaluating the caption generation model
- For the prediction part, it is true that with the FlickR image I tried, it works perfect:


Caption prediction 29-08-2020
- However when I took 5 others photos from my own photothèque and made caption prediction, the results were disappointing.
Part IX: Machine Translation
Chapter 27: Neural Machine Translation
- « Automatic or machine translation is perhaps one of the most challenging artificial intelligence tasks given the fluidity of human language. Classically, rule-based systems were used for this task, which were replaced in the 1990s with statistical methods. More recently, deep neural network models achieve state-of-the-art results in a field that is aptly named neural machine translation »
- « Statistical machine translation, or SMT for short, is the use of statistical models that learn to translate text from a source language to a target language given a large corpus of examples. »
- « The approach is data-driven, requiring only a corpus of examples with both source and target language text. This means linguists are not longer required to specify the rules of translation. »
- « Neural machine translation, or NMT for short, is the use of neural network models to learn a statistical model for machine translation.«
- « Key to the encoder-decoder architecture is the ability of the model to encode the source text into an internat fixed-length representation called the context vector.«
Chapter 28: What are Encoder-Decoder Models for Neural Machine Translation
- « The encoder-decoder recurrent neural network architecture is the core technology inside Google’s translate service.«
- Two models:
Chapter 29: How to Configure Encoder-Decoder Model for Machine Translation
- « Research scientists have used Google-scale hardware to provide a set of heuristics for how to configure the encoder-decoder model for neural machine translation and for sequence prediction generally«
Chapter 30: Develop a Neural Machine Translation Model
- « Each input and output sequence must be encoded to integers and padded to the maximum phrase length. This is because we will use a word embedding for the input sequences and one hot encode the output sequences«
- « The output sequence needs to be one hot encoded. This is because the model will predict the probability of each word in the vocabulary as output »
- « The model is trained using the efficient Adam approach to stochastic gradient descent and minimizes the categorical loss function because we have framed the prediction problem as multiclass classification. »
- Running the example for a translation of German to English gave me the following result:

Source, Target and Expected translation - BLEU scores
- You can observe from the above translation examples that there is still room for human translation work.
Conclusion
- This is the end of the journey in « Deep Learning for Natural Language Processing » and I did not regret it.
- I learned not only a lot of concepts around NLP, but I also had the opportunity to put in practice those concepts with the code examples.
- The systemic approach from Jason Brownlee is well adapted for me with the mix of concepts simply explained and then put in practice.
- The provided Python code examples are easy to read and all the different code sequences clearly separated for understanding.
- Each chapter comes with a « Further reading » section which is very rich and you can dig in related research documents.
- Big thanks to Jason Brownlee for this journey.